The company in a YAML file
H0LD1NG is an operating system for companies staffed by AI agents. You describe an organization in a single config file — its mission, roles, cadences, budgets — and a generic runtime turns it into a living firm: agents that wake on schedule, coordinate through a task board and memos, ship files into a shared workspace, and account for every token they burn. We started four of them and watched.
There is no per-company code
Most agent frameworks make you write an application. H0LD1NG makes you write an
org chart. The README states the load-bearing claim up front: “The
difference between a software house and an SEO agency is entirely in the config —
there is no per-company code.” The runtime is 100% generic. A company is a single
file in companies/<id>.yaml declaring a mission, a handful of roles
(each one of five archetypes: executive, manager,
maker, reviewer, researcher), how often each
role wakes up, which events it reacts to, and how much money it may spend.
From that file the orchestrator staffs a firm. A role with instances: 2
becomes two named personas with deterministically generated portraits — same company,
role, and seat always produces the same person. Each wake-up is a short, stateless
agent session — on Claude via the
Claude Agent SDK,
or on OpenAI, Gemini, Ollama, or xAI Grok via their APIs when the role’s
model: says so (openai/gpt-5.4).
Continuity does not live in model context; it lives in the task board, the memos, and
the files on disk. The system prompt makes the stakes existential for the agent:
“Coordinate with other roles ONLY through the task board and memos (mcp__company__* tools). Other roles cannot see your session — anything not written to the board, a memo, or a file is lost.” — role system prompt, packages/core
That one constraint shapes the whole design: any run can crash without corrupting the company, because no run ever holds state that matters.
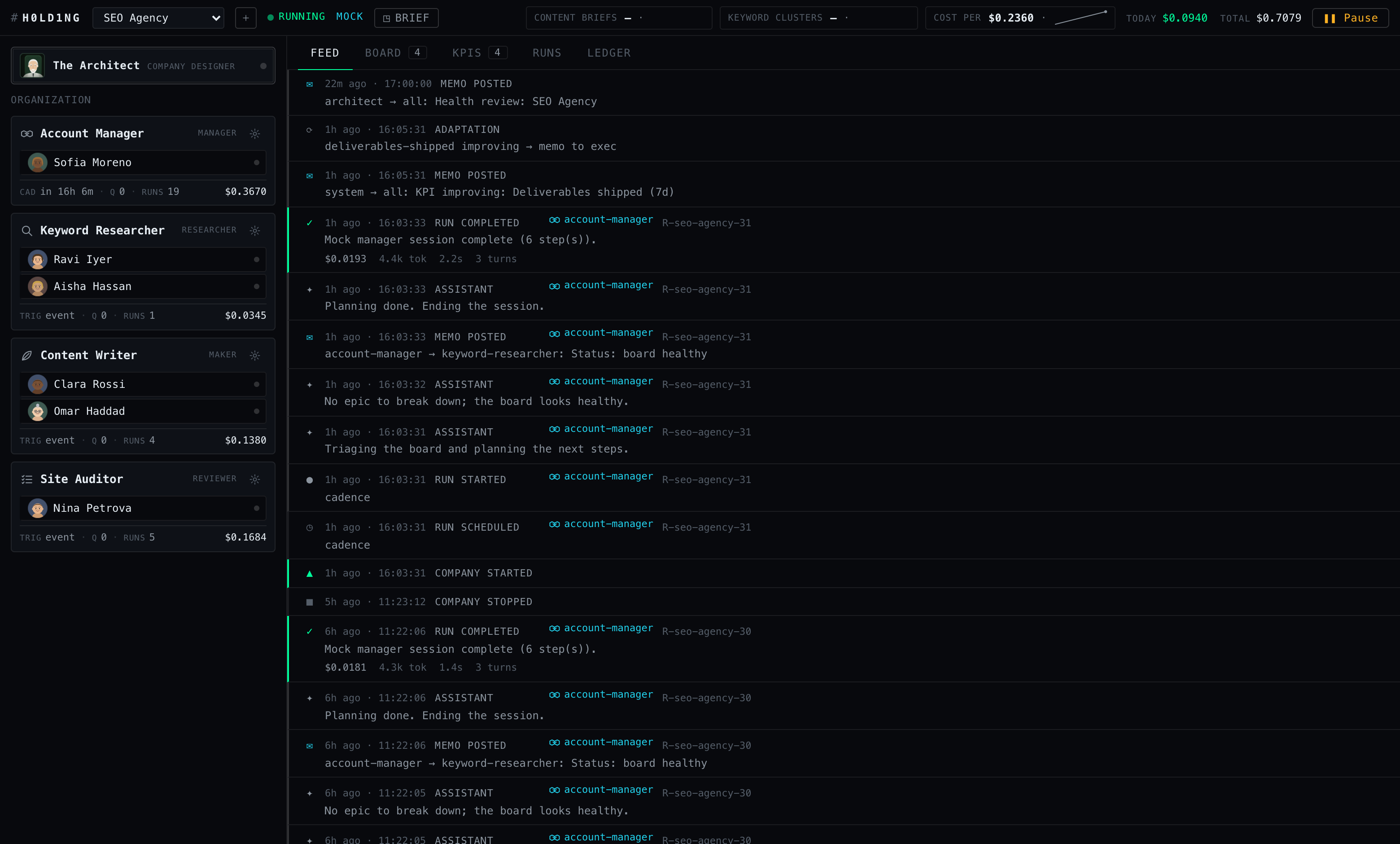
Boot a firm for $0.00
Everything in this article was produced in mock mode — zero API calls, zero dollars, no authentication. We started four of the five bundled companies in one daemon:
$ node packages/cli/dist/index.js start seo-agency trading-glass typing-cat boardgames-zone --mock HOLDING daemon MOCK MODE (no API calls, no cost) ● SEO Agency (seo-agency) — 4 roles, 6 instances daily budget: $8.00 ● Trading Glass (trading-glass) — 5 roles, 6 instances daily budget: $8.00 ● The Typing Cat (typing-cat) — 5 roles, 6 instances daily budget: $8.00 ● Boardgames Zone (boardgames-zone) — 5 roles, 6 instances daily budget: $8.00 ✦ The Architect — describe a company, get a running one (mock) dashboard: http://localhost:4733 auth: bearer token (the dashboard uses it automatically) token: a3f06c9e4b1d27c85e90f4a6b2d81c3e7f5a0942d6b81c4f
Mock mode is not a stub. The same orchestrator schedules the same roles through the
same queues; the only swap is the runner. Mock runs are scripted per archetype, but
they perform real board and memo mutations — an executive posts a directive
and, about 60% of the time, seeds an epic; a manager decomposes it into two or three
child tasks; a maker fakes a couple of
Write calls and an npm test (“Test suite passed (mock).”);
a reviewer approves about 70% of what it sees and bounces the rest. Runs sleep
400–1500 ms between events so the dashboard sees work unfold live, and each one
books fake token usage under the model name mock-sonnet, priced at
Sonnet’s literal public rates: $3 per million input tokens, $15 per million output.
On the dashboard, a mock company is indistinguishable from a real one — which is the
point.
Real mode is one flag away — drop --mock. A role’s model:
picks the provider: bare Claude aliases (sonnet, haiku) run
on the Claude Agent SDK, which spawns the installed claude CLI and
inherits its authentication (a logged-in Claude Code subscription or an
ANTHROPIC_API_KEY), while openai/gpt-5.4,
gemini/gemini-3-flash-preview, ollama/llama3.1:8b or
grok/grok-4.1-fast run on that provider’s OpenAI-compatible API through
H0LD1NG’s own agentic loop — the same company tools, plus sandboxed file tools, so a
role behaves the same wherever it runs. Ollama is local and genuinely free; a paid
model with no known price fails the run rather than billing $0 and slipping past the
spend caps.
Four pillars
Roles, prompts, cadences, triggers, headcounts, budgets — all of it lives in
companies/<id>.yaml. The runtime never branches on which company
it is running.
Every run writes a full-fidelity transcript. Every meaningful action becomes an append-only event. Every run produces a ledger entry with exact token usage and cost. Nothing is hidden.
A run is a short autonomous session. Continuity lives in the board, memos, and workspace files — never in model context. A crashed run cannot corrupt the company.
Per-run turn and dollar caps — enforced by the SDK for Claude, by H0LD1NG’s own loop for API providers. A hard per-company daily budget that reserves each run’s cap up front and auto-pauses. Per-role instance caps. Agents sandboxed to their company’s workspace; the control plane loopback-bound and token-gated.
Meet the staff
Five companies ship with the repo, and they are deliberately not clones. The flagship
Software House is the only firm with a $10/day budget and the only one shipping real
TypeScript — devlog, a tiny static-site-generator CLI whose v1 is “done”
only when it builds, has tests, has a README, and QA approved it. The SEO Agency
serves two fictional clients (BrewHaus Coffee and FitPlan Studio) and gives its
reviewer a standing order: “Never approve your own work.” Trading Glass
wraps its whole org in a safety scaffold — a CRITICAL SAFETY
CONSTRAINT in its design brief, echoed as a hard “never produce financial
advice or live-trading signals” rule in every single role; its engineer may touch
synthetic data only, never live trading systems or real money. Boardgames Zone wasn’t hand-written at all: it was designed by The Architect
and carries its founding prompt in the config.
| company | id | roles · headcount | reviewer | kpis | budget/day |
|---|---|---|---|---|---|
| Software House | software-house | ceo · pm · engineer×2 · qa — 5 | qa (haiku) | 3 | $10.00 |
| SEO Agency | seo-agency | acct-mgr · kw-researcher×2 · writer×2 · auditor — 6 | site-auditor (haiku) | 4 | $8.00 |
| Trading Glass | trading-glass | research-lead · analyst×2 · strategist · growth · engineer — 6 | — | 5 | $8.00 |
| The Typing Cat | typing-cat | growth-lead · analyst · writer×2 · ux-ideator · engineer — 6 | — | 4 | $8.00 |
| Boardgames Zone | boardgames-zone | growth-lead · analyst · writer×2 · curator · engineer — 6 | — | 5 | $8.00 |
Even the office hours are staggered: Trading Glass’s research lead clocks in at 08:30, the SEO account manager at 09:30, Boardgames Zone’s growth lead doesn’t start until 10:30. All five route work the same way — through a five-column kanban whose every ticket is a job contract: description, deliverables checklist, acceptance criteria, comment thread, linked runs.
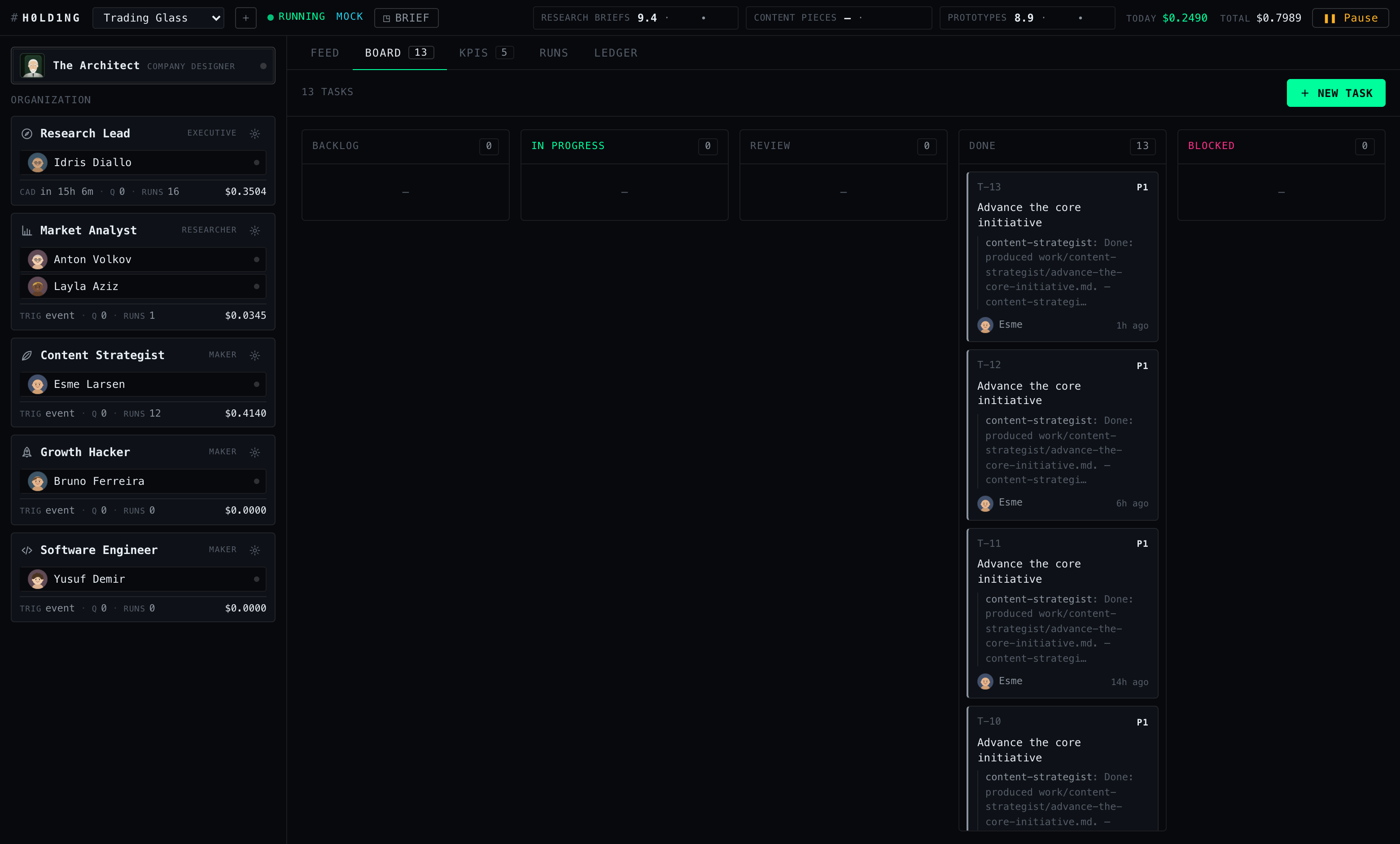
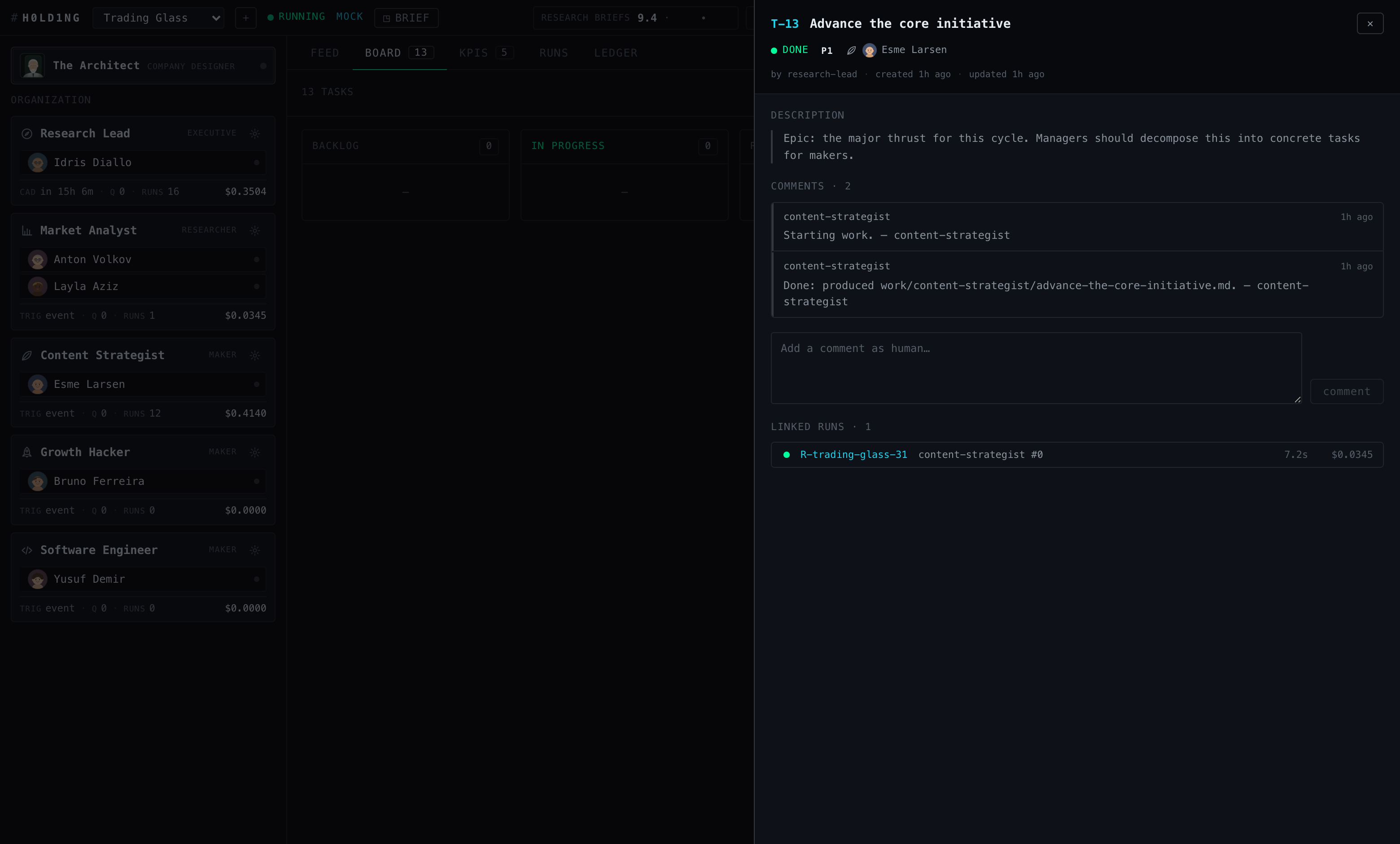
#task-T-13.A 5-second heartbeat and two anti-loop guards
The orchestrator is a single 5-second tick. Each role declares either a cadence in a
tiny DSL — every 2h, hourly@:15, daily@09:30 —
or event triggers (“wake when task.created with
role: engineer”), or both. When a cadence fires and a seat is free,
the role runs; if all instances are busy, the system emits run.skipped
and recomputes the next fire rather than piling work up. Event triggers queue FIFO
per role, capped at 50.
Two guards keep an event-driven org from feeding back into itself. A role’s own run
can never re-trigger that role — one line in the dispatcher. And a sliding-window
loop guard caps re-triggers of the same role-and-subject at six per ten minutes,
dropping the excess with reason loop_guard — in the source’s own words,
“so a runaway loop dampens itself instead of burning spend.”
The money rails
Spend is bounded at three altitudes. Each run carries maxTurns and
maxBudgetUsdPerRun (all five companies default to 40 turns and $1.00 on
Sonnet), enforced inside the SDK for Claude models and inside H0LD1NG’s own loop for
API providers — a run that would cross its dollar cap is stopped with
error_max_budget_usd. Above that, budgets.dailyUsd is a
hard ceiling, not a suggestion: every dispatched run reserves its full per-run cap
until it settles, and the guard counts settled plus reserved spend, so a
burst of parallel dispatches can’t overshoot against a stale total. A
budget.warning fires at ~80%; crossing the line emits
budget.exceeded once and auto-pauses — in-flight runs finish, no new
ones dispatch. And notably, an unset daily budget does not mean
unlimited: the guard backstops every company with a default $25/day cap and flags the
event as defaulted.
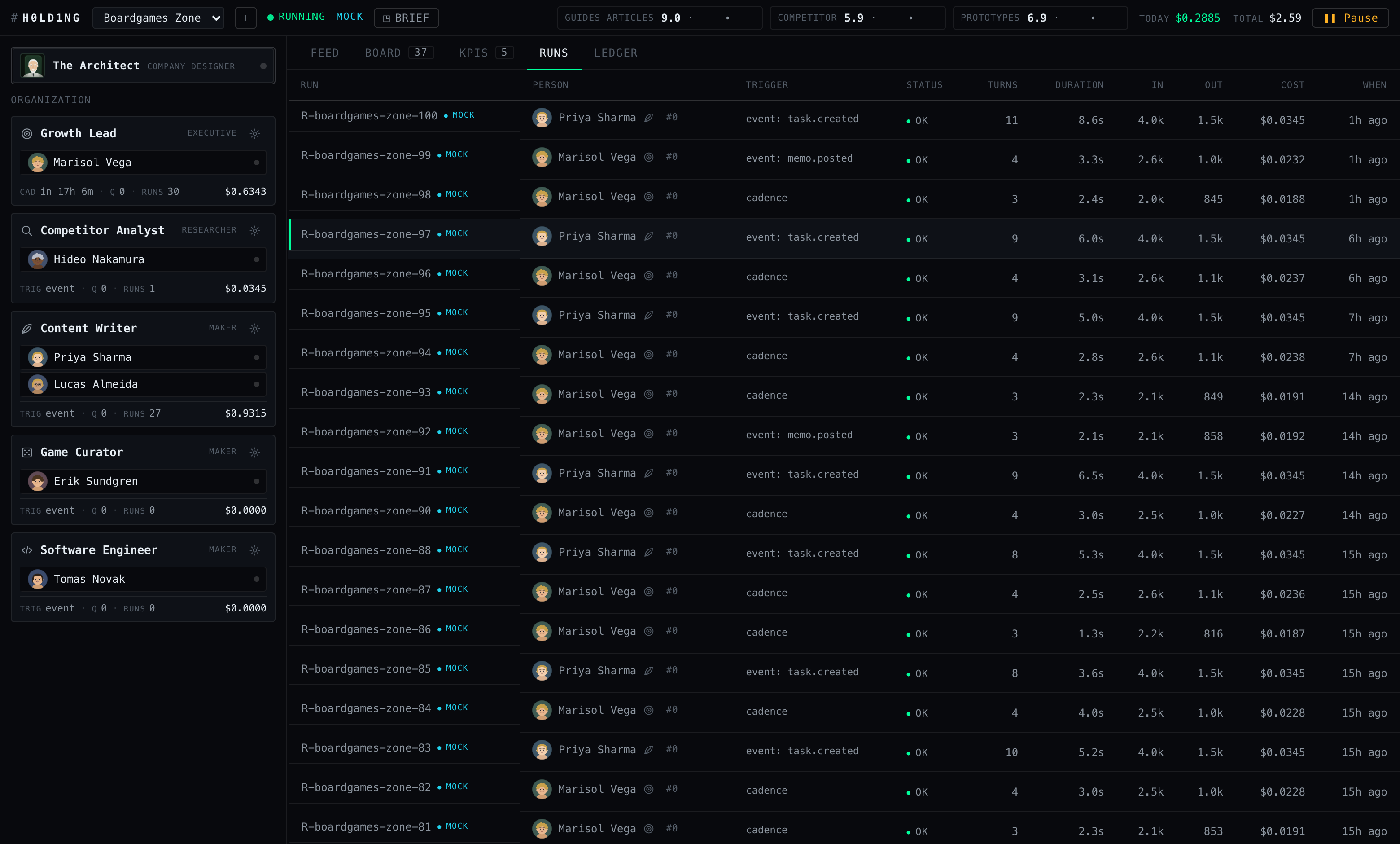
event: task.created, event: memo.posted), status, turns, duration, tokens in/out, and cost to four decimals.Every action and every token, on the record
Each company’s entire observable life sits under workspaces/<id>/state/
in human-readable files: an append-only events.jsonl, a full per-run
transcript in runs/<runId>.jsonl with nothing truncated, plus
ledger.jsonl, kpis.jsonl and adaptations.jsonl.
Snapshots (tasks.json, memos.json) are written atomically —
temp file, then rename — so a crash mid-write can never leave half a file. The feed
shows truncated previews (500 chars of assistant text, 600 of tool payloads); the
transcript keeps full fidelity.
Open any run and the dashboard reconstructs its session from the raw SDK messages, pairing each tool call with its result, with token usage badged across the header:
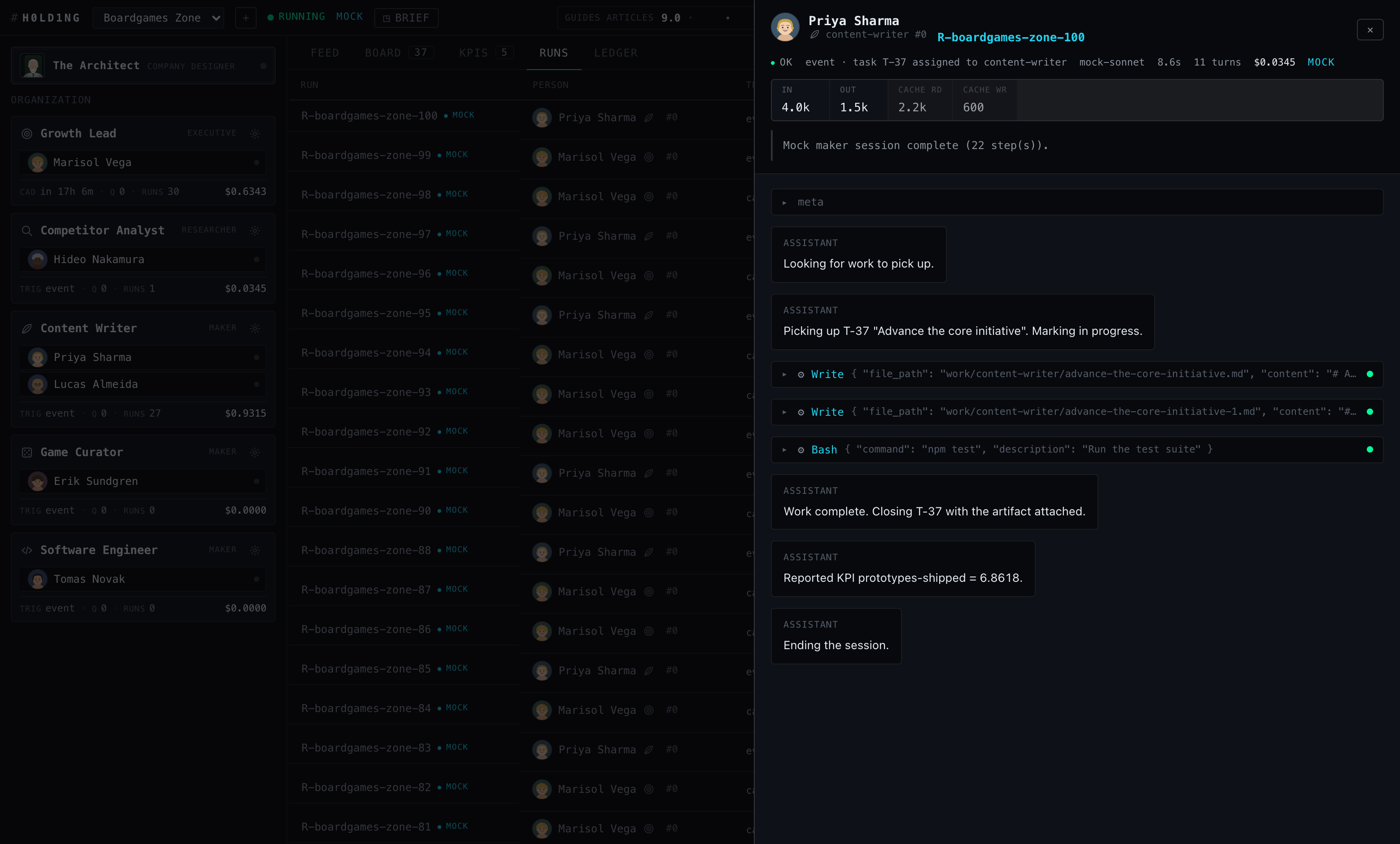
R-boardgames-zone-100, content-writer Priya Sharma. The drawer replays the transcript — picking up ticket T-37, two Write calls and a Bash check, closing the ticket with the artifact attached, reporting a KPI, ending the session. Header badges: tokens in / out / cache read / cache write.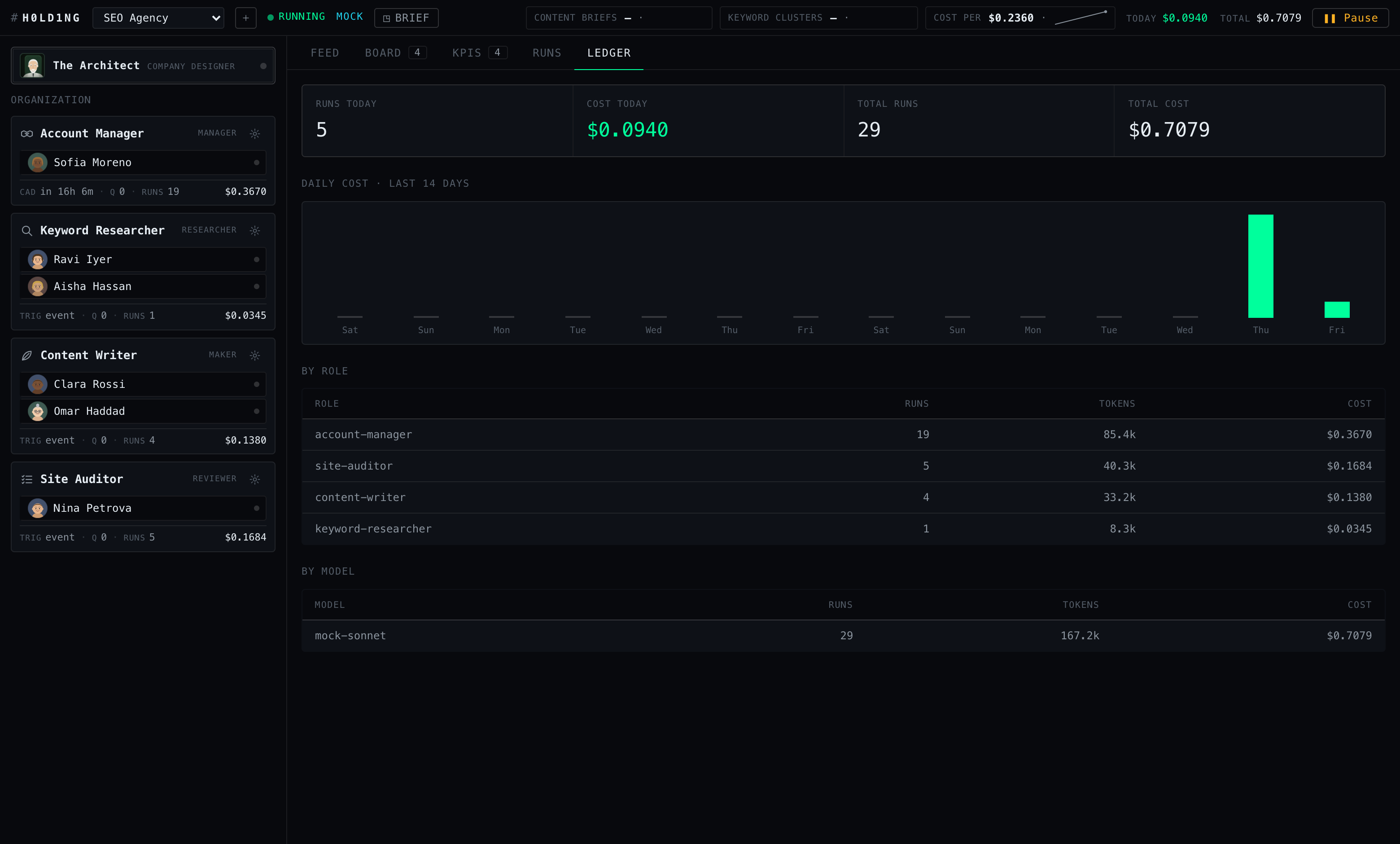
mock-sonnet, billed at Sonnet’s real rates, costing nothing.
The dashboard itself is five tabs — Feed, Board, KPIs, Runs, Ledger — over one SSE
stream per company, with hash deep-links (#board,
#task-T-5, #architect) put there, the source notes,
explicitly so screenshots can target any view. The control plane underneath is locked
down by default: the daemon binds 127.0.0.1 and gates every
/api/* call behind a bearer token — generated per start, printed in the
banner, and injected into the served dashboard so the UI authenticates with zero
setup. Even failures are accounted: an aborted or crashed run still writes a ledger
entry, at zero cost, with its error subtype — and if the whole daemon dies mid-run,
an inflight marker written at dispatch lets the next start reconcile the interrupted
runs into the ledger as failed, so spent money stays on the books and the daily cap
doesn’t relax across restarts.
KPIs, a vitality index, and a learning ledger
Companies measure themselves. A YAML kpis block declares up to a
handful of metrics — at most three pinned to the command bar — that are either
derived (computed read-only from the ledger and board: tasks done, cost per
done task, run success rate…) or agent-reported via a
kpi_report tool, bucketed by UTC day, last value of the day wins.
Trends are mechanical: the mean of the last three daily values against the mean of
the prior four; ±10% decides improving, degrading, or steady.
Above the KPIs sits a single 0–100 vitality score: throughput
weighted 0.25, run success 0.20, cycle time, first-pass rate and cost-efficiency
0.15 each, budget headroom 0.10. The reference points are opinionated — throughput
saturates at five done tasks a day, cycle time scores zero at 72 hours, cost per done
task scores zero at $5 — and components with no data yet are dropped with the weights
renormalized, so a young company is scored only on what it can show. First-pass rate
is detected by regex over ticket comments: a done task counts as bounced if anything
matched /changes requested|needs changes|bounce|sending it back|re-?work/i.
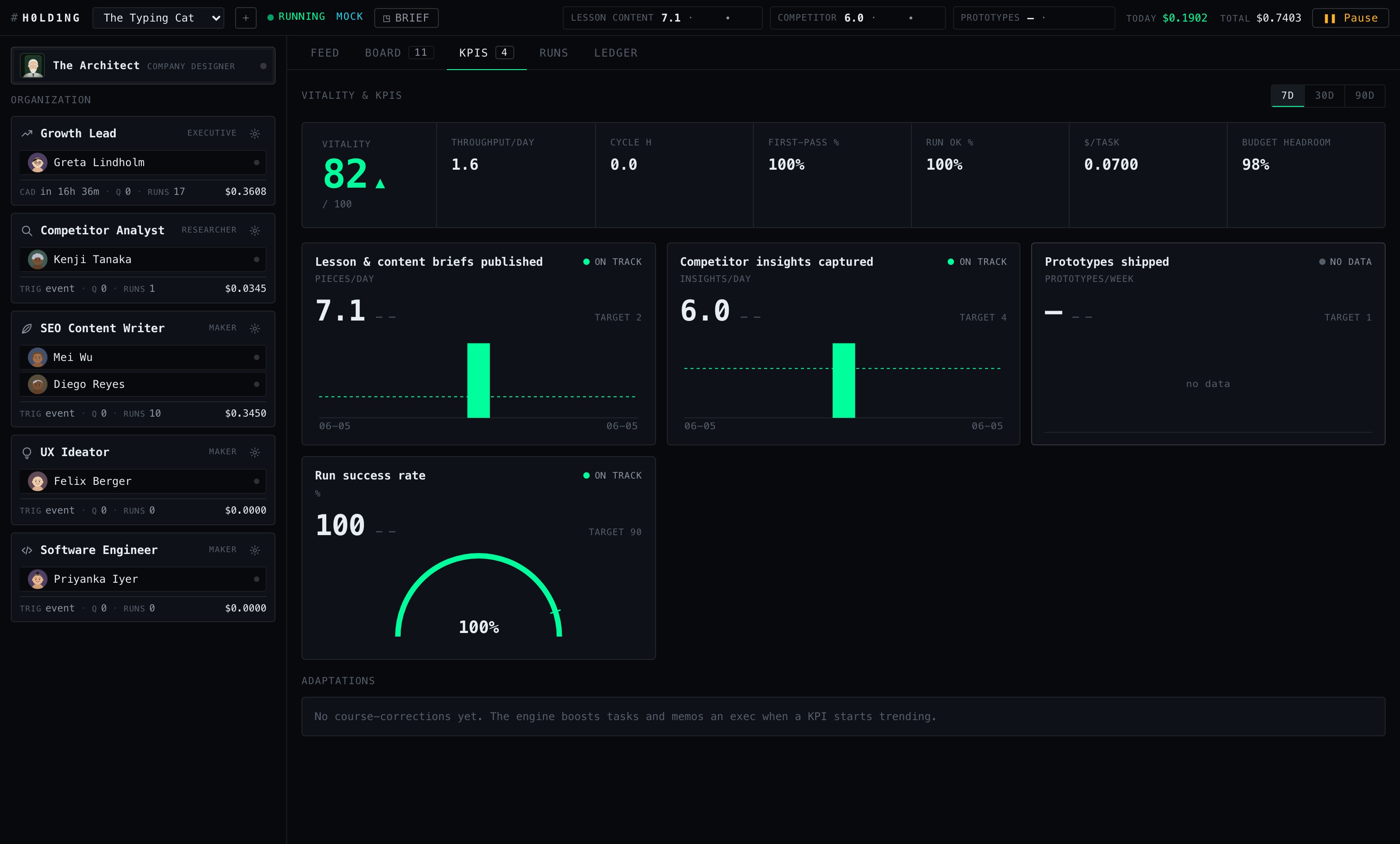
That last line is the adaptation engine — the part that closes the loop. Every 30
minutes (first pass ~2 minutes after start) it reads each KPI’s 14-day trend. When
one is moving — improving or degrading, never steady — and hasn’t been acted
on in 12 hours, it bumps the priority of open tasks tagged with that KPI one step and
posts a memo to the company’s executive: course-correction wording when degrading,
double-down when improving. Each intervention is appended to
adaptations.jsonl — a learning ledger of what the company tried and when.
The Architect: a company that designs companies
The strangest entity in the holding is its first employee. The Architect is itself a
“company” — reserved id _architect, same event bus, same transcripts,
same ledger — whose persona is instructed to “build the smallest organization
that ships the work” and then stop. It has exactly one tool:
submit_company, which takes a YAML document, validates it against the
real config schema, and writes it to companies/. Invalid submissions
bounce back with exact field paths to fix. Each design session is capped at 25 turns
and $1.50.
Type a one-line brief into the dashboard — “a boutique podcast studio that
researches topics, writes scripts, and edits episodes” — and the Architect
drafts the org: roles, archetypes, cadences, prompts, KPIs, budgets. In mock mode the
new company hot-starts immediately, for free. In real mode the default is
review-first: the YAML sits on disk until a human clicks Start company, so a
freshly designed firm never burns API money before you’ve read its charter
(--auto-start-designs flips that). The Architect also redesigns running
companies in place — board, memos, ledger, workspace, even live dashboard connections
survive the swap — and reviews their health on a cadence, correlating each past
adaptation with what the KPI did afterwards, then memo-ing the executive about which
levers actually worked.
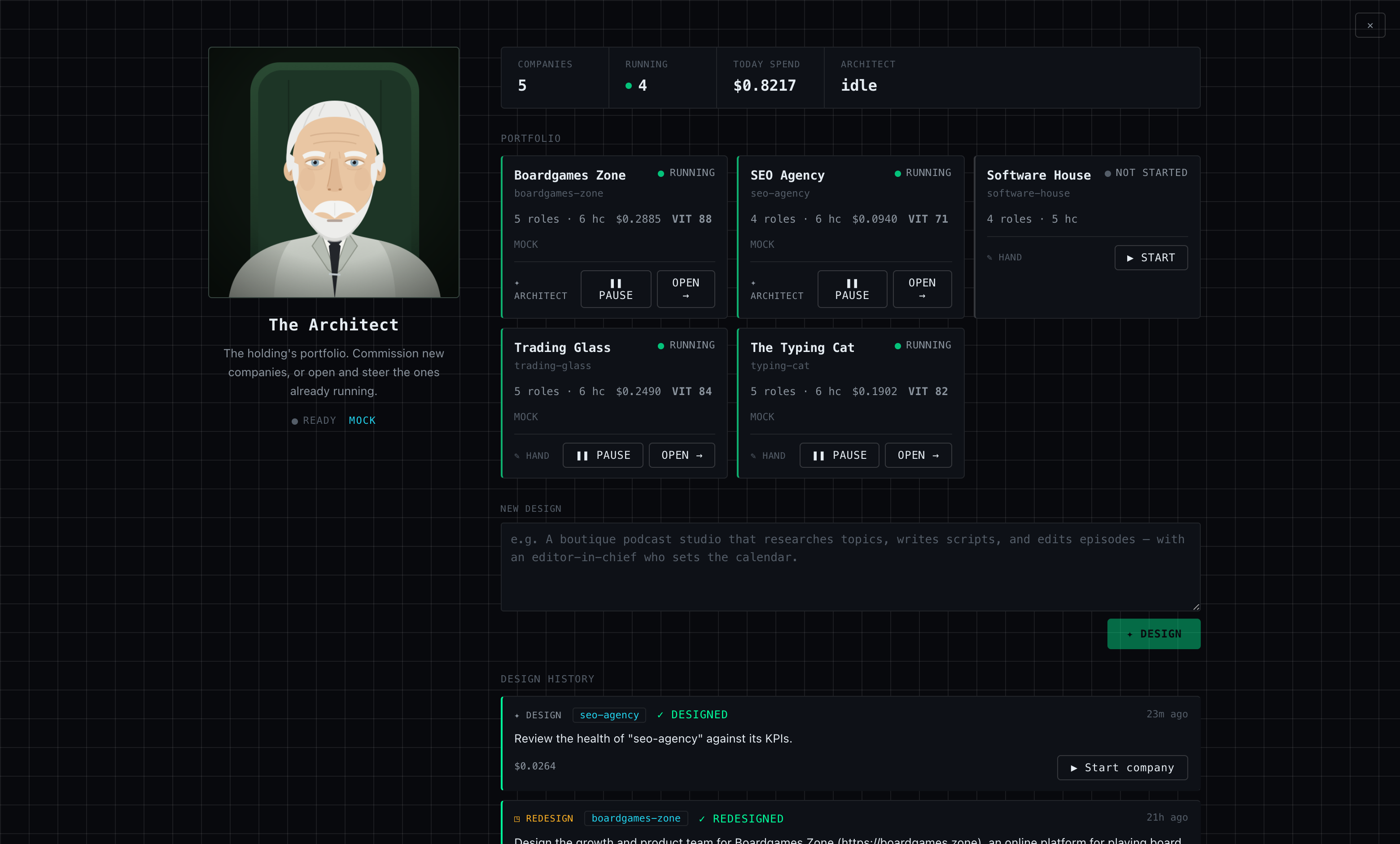
boardgames-zone ($0.0529) and a health review of seo-agency ($0.0264).
Companies in the holding can even trade with each other: a ticket can be outsourced
to a sibling company through the orchestrator acting as broker — the target gets a
linked task prefixed [from seo-agency], and on completion the artifacts
are copied back into the source’s inbox/outsourced/. One hop only; the
broker refuses chains.
Organizations as text
After a few hours, our four mock companies had filed 29 runs at the SEO Agency alone, pushed boards of tickets to done, reported KPIs, and triggered the Architect’s health reviews — all for $0.00, all replayable from append-only files. The provocation of H0LD1NG isn’t any single mechanism; it’s the altitude. Code defines physics — scheduling, budgets, accounting, guards. Everything we’d recognize as “the company” — who works there, what they care about, how cautious they are, when they clock in — is text. Version-controlled, diffable, designable by another agent.
And when the experiment is over, the reset ritual is one line: stop the daemon and
rm -rf workspaces/<id>. The org chart remains; the company forgets
it ever lived. Next start, the founder memos go out again.
$ node packages/cli/dist/index.js start software-house --mock $ open http://localhost:4733 # watch the org rail come alive